Algorithms are everywhere in our daily life. Amazon makes recommendations for books. Netflix recommends movies. News and trending stories appear on our Twitter and Facebook feeds. Algorithms determine what information we see, and in what order. This includes search engines like Google, Google Scholar, and library databases. A 2020 study found that college students placed trust in Google as "the arbiter of truth." But is this trust misplaced? Algorithms are designed by humans and therefore reflect the assumptions and biases of their designers. Algorithms are not neutral, but this does not mean they are not useful tools for research or everyday life. It helps to know their limitations and biases. In this workshop, you will learn how algorithms can perpetuate bias and discrimination, and you will identify the potential causes of algorithmic bias as well as some preventive strategies. This event is open to all.
Algorithm: The set of logical rules used to organize and act on a body of data to solve a problem or accomplish a goal that is usually carried out by a machine
Example Algorithm:
Program that encodes a person's options for navigating the library.
Goals = food or research
If goal = food, then location = Starbucks.
If goal = research: if on campus, then location = Information Desk; if off campus, then location = online chat
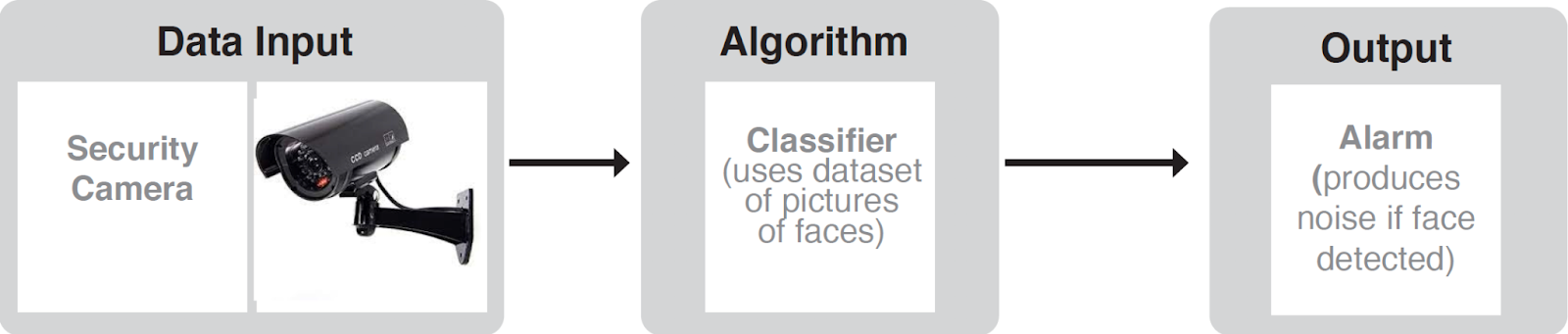
Algorithm Infrastructure- Example:
Graphic adapted from: Long, D., Moon, J., & Magerko, B. (2021). Introducing AI worksheet (model activity). In EEAI-2021: The Eleventh Symposium on Educational Advances in Artificial Intelligence (p. 15706). Association for the Advancement of Artificial Intelligence. http://modelai.gettysburg.edu/2021/intro/
Types of Algorithms:
Algorithmic Bias: Occurs when a computer system reflects the implicit values of the humans who are involved in collecting, selecting, or using data
Causes of Bias:
Personalization: Process (used in targeted digital advertising) of displaying search results or modifying the behavior of an online platform to match an individual’s expressed or presumed preferences, established through creating digital profiles and using that data to predict whether and how an individual will act on algorithmically selected information